The Two Subsystems Missing from Modern AI
Takeaways from Adam Marblestone's conversation with Dwarkesh Patel

I recently watched Dwarkesh’s pod with Adam Marblestone, a biophysicist and the CEO of Convergent Research. Here were my key takeaways:
Current AI systems are quite detached from biological mechanisms. Outside of the neuron (1958), algorithms like backpropagation and architectures are being mapped onto our understanding of the brain, not the other way around [00:01:00]
The brain likely has two subsystems: a “Steering Subsystem” (hypothalamus, brainstem) with hardcoded reward functions, and a “Learning Subsystem” (cortex) that learns by predicting what the Steering Subsystem will do. This answers Ilya’s question about how evolution encodes abstract desires without knowing the specific concepts the cortex will learn. This isn’t just speculation: single-cell atlas data shows thousands of specialized cell types in the Steering Subsystem, compared to the relatively repetitive six-layer architecture of the cortex [~09:15]
One concrete mechanism for sample efficiency: the hippocampus captures short-term experiences, then “replays” them to the cortex during sleep. This two-stage process trains the long-term world model without needing millions of repeated exposures [~01:38:18]
Bidirectional inference: current autoregressive models still fully describe the distribution, but it’s somewhat intractable to work backward from your goals. Google and others experimented with diffusion, and Yann LeCun’s JEPA works in a more latent space rather than discrete tokens [03:30]
The idea of not just predicting the output but also auxiliary states akin to what we see in brain scans (MRIs) would help with learning things the “right way” rather than the shortcuts used by “black box” methods. This is also a path to sample efficiency: auxiliary supervision forces representations that generalize rather than memorizing dataset-specific shortcuts [~01:23:28]
The Upshot
Auxiliary supervision would greatly reduce memorization1 (taking shortcuts instead of true understanding2, which is more difficult) by conditioning predictions on complex outside signals3 that force the model to learn necessary intermediate variables. Rather than learning the dataset in a single shot—which incentivizes finding shortcuts during backpropagation—this approach encourages the more desirable “meta-learning” (evolution doesn’t encode knowledge directly; it encodes the loss functions that make learning efficient).
What do you think about these approaches to advancing AI?
Are they promising and crucial for enabling the next step change in capabilities?
Or will the Bitter Lesson hold true (simpler is better) and the human brain will prove to be a marvel of billions of years of evolution in response to an ever-changing world—an approach that may be quite difficult or wasteful to replicate?
Are deep learning systems are largely just compression algorithms at their core?
The phenomena of “Grokking” seems to a be crucial aspect of any deep learning systems where it initially memorizes then eventually (after a really long time) begins to deeply understand the underlying mechanism. Welch Labs made a great video on this.
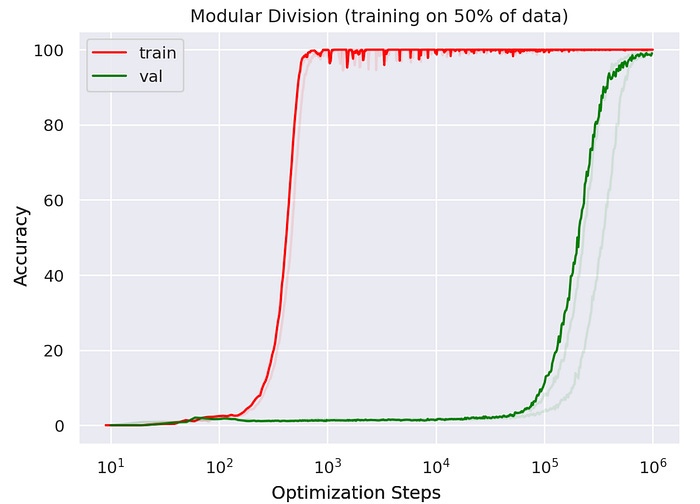
As opposed to a simple binary yes/no target used for distinguishing between a cat an dog that only requires predicting up to 1 bit per task.